 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
Jun 01, 2026Vision-language-action (VLA) models are built on the premise that semantic understanding from pretrained language or vision-language backbones should guide robot action prediction. Yet robot fine-tuning is optimized as imitation over task-specific action distributions, and many evaluations can be solved through visual or instruction-action shortcuts. We introduce RoboSemanticBench (RSB), an embodied benchmark for diagnosing semantic grounding in action prediction: whether post-trained VLA models can use complex instruction semantics to select and manipulate the correct physical target. In each episode, a robot receives a multiple-choice math or general-knowledge question, observes candidate answer blocks, and must grasp the block corresponding to the correct answer. RSB covers controlled arithmetic, grade-school mathematical understanding, and commonsense or factual understanding under four-choice and ten-choice suites. Across representative VLA models, we find that many policies learn to grasp candidate blocks but select the semantically correct block at near-random or below-random rates after controlling for grasp success, revealing a persistent gap between backbone-level semantic competence and action prediction.
IntentVLA: Short-Horizon Intent Modeling for Aliased Robot Manipulation
May 14, 2026Robot imitation data are often multimodal: similar visual-language observations may be followed by different action chunks because human demonstrators act with different short-horizon intents, task phases, or recent context. Existing frame-conditioned VLA policies infer each chunk from the current observation and instruction alone, so under partial observability they may resample different intents across adjacent replanning steps, leading to inter-chunk conflict and unstable execution. We introduce IntentVLA, a history-conditioned VLA framework that encodes recent visual observations into a compact short-horizon intent representation and uses it to condition chunk generation. We further introduce AliasBench, a 12-task ambiguity-aware benchmark on RoboTwin2 with matched training data and evaluation environments that isolate short-horizon observation aliasing. Across AliasBench, SimplerEnv, LIBERO, and RoboCasa, IntentVLA improves rollout stability and outperforms strong VLA baselines
FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
May 13, 2026Vision-Language-Action (VLA) policies are commonly trained from dense robot demonstration trajectories, often collected through teleoperation, by sampling every recorded frame as if it provided equally useful supervision. We argue that this convention creates a temporal supervision imbalance: long low-change segments dominate the training stream, while manipulation-critical transitions such as alignment, contact, grasping, and release appear only sparsely. We introduce FrameSkip, a data-layer frame selection framework that scores trajectory frames using action variation, visual-action coherence, task-progress priors, and gripper-transition preservation, then remaps training samples toward high-importance frames under a target retention ratio. Because FrameSkip operates only in the dataloader, it leaves the VLA architecture, action head, training objective, and inference procedure unchanged. Across RoboCasa-GR1, SimplerEnv, and LIBERO, FrameSkip improves the success-retention trade-off over full-frame training and simpler frame selection variants, achieving a macro-average success rate of 76.15% across the three benchmarks compared with 66.50% for full-frame training while using a compressed trajectory view that retains 20% of unique frames in the main setting.
3D-Mix for VLA: A Plug-and-Play Module for Integrating VGGT-based 3D Information into Vision-Language-Action Models
Mar 25, 2026Vision-Language-Action (VLA) models leverage Multimodal Large Language Models (MLLMs) for robotic control, but recent studies reveal that MLLMs exhibit limited spatial intelligence due to training predominantly on 2D data, resulting in inadequate 3D perception for manipulation tasks. While recent approaches incorporate specialized 3D vision models such as VGGT to enhance spatial understanding, they employ diverse integration mechanisms without systematic investigation, leaving the optimal fusion strategy unclear. We conduct a comprehensive pilot study comparing nine VGGT integration schemes on standardized benchmarks and find that semantic-conditioned gated fusion, which adaptively balances 2D semantic and 3D geometric features based on task context, achieved the strongest performance among all nine evaluated fusion schemes in our pilot study. We present 3D-Mix, a plug-and-play module that integrates into diverse VLA architectures (GR00T-style and $π$-style) without modifying existing MLLM or action expert components. Experiments across six MLLM series (nine model variants, 2B--8B parameters) on SIMPLER and LIBERO show that 3D-Mix delivers consistent performance gains, averaging +7.0% on the out-of-domain (OOD) SIMPLER benchmark across all nine GR00T-style variants, establishing a principled approach for enhancing spatial intelligence in VLA systems.
ScalSelect: Scalable Training-Free Multimodal Data Selection for Efficient Visual Instruction Tuning
Feb 12, 2026Large-scale Visual Instruction Tuning (VIT) has become a key paradigm for advancing the performance of vision-language models (VLMs) across various multimodal tasks. However, training on the large-scale datasets is computationally expensive and inefficient due to redundancy in the data, which motivates the need for multimodal data selection to improve training efficiency. Existing data selection methods for VIT either require costly training or gradient computation. Training-free alternatives often depend on proxy models or datasets, instruction-agnostic representations, and pairwise similarity with quadratic complexity, limiting scalability and representation fidelity. In this work, we propose ScalSelect, a scalable training-free multimodal data selection method with linear-time complexity with respect to the number of samples, eliminating the need for external models or auxiliary datasets. ScalSelect first constructs sample representations by extracting visual features most attended by instruction tokens in the target VLM, capturing instruction-relevant information. It then identifies samples whose representations best approximate the dominant subspace of the full dataset representations, enabling scalable importance scoring without pairwise comparisons. Extensive experiments across multiple VLMs, datasets, and selection budgets demonstrate that ScalSelect achieves over 97.5% of the performance of training on the full dataset using only 16% of the data, and even outperforms full-data training in some settings. The code is available at \href{https://github.com/ChangtiWu/ScalSelect}{ScalSelect}.
LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Jan 27, 2026Vision-Language-Action (VLA) models have shown promise in robot manipulation but often struggle to generalize to new instructions or complex multi-task scenarios. We identify a critical pathology in current training paradigms where goal-driven data collection creates a dataset bias. In such datasets, language instructions are highly predictable from visual observations alone, causing the conditional mutual information between instructions and actions to vanish, a phenomenon we term Information Collapse. Consequently, models degenerate into vision-only policies that ignore language constraints and fail in out-of-distribution (OOD) settings. To address this, we propose LangForce, a novel framework that enforces instruction following via Bayesian decomposition. By introducing learnable Latent Action Queries, we construct a dual-branch architecture to estimate both a vision-only prior $p(a \mid v)$ and a language-conditioned posterior $π(a \mid v, \ell)$. We then optimize the policy to maximize the conditional Pointwise Mutual Information (PMI) between actions and instructions. This objective effectively penalizes the vision shortcut and rewards actions that explicitly explain the language command. Without requiring new data, LangForce significantly improves generalization. Extensive experiments across on SimplerEnv and RoboCasa demonstrate substantial gains, including an 11.3% improvement on the challenging OOD SimplerEnv benchmark, validating the ability of our approach to robustly ground language in action.
BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Jan 21, 2026Vision-Language-Action (VLA) models have shown promise in robot manipulation but often struggle to generalize to new instructions or complex multi-task scenarios. We identify a critical pathology in current training paradigms where goal-driven data collection creates a dataset bias. In such datasets, language instructions are highly predictable from visual observations alone, causing the conditional mutual information between instructions and actions to vanish, a phenomenon we term Information Collapse. Consequently, models degenerate into vision-only policies that ignore language constraints and fail in out-of-distribution (OOD) settings. To address this, we propose BayesianVLA, a novel framework that enforces instruction following via Bayesian decomposition. By introducing learnable Latent Action Queries, we construct a dual-branch architecture to estimate both a vision-only prior $p(a \mid v)$ and a language-conditioned posterior $π(a \mid v, \ell)$. We then optimize the policy to maximize the conditional Pointwise Mutual Information (PMI) between actions and instructions. This objective effectively penalizes the vision shortcut and rewards actions that explicitly explain the language command. Without requiring new data, BayesianVLA significantly improves generalization. Extensive experiments across on SimplerEnv and RoboCasa demonstrate substantial gains, including an 11.3% improvement on the challenging OOD SimplerEnv benchmark, validating the ability of our approach to robustly ground language in action.
TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
Jan 20, 2026Standard Vision-Language-Action (VLA) models typically fine-tune a monolithic Vision-Language Model (VLM) backbone explicitly for robotic control. However, this approach creates a critical tension between maintaining high-level general semantic understanding and learning low-level, fine-grained sensorimotor skills, often leading to "catastrophic forgetting" of the model's open-world capabilities. To resolve this conflict, we introduce TwinBrainVLA, a novel architecture that coordinates a generalist VLM retaining universal semantic understanding and a specialist VLM dedicated to embodied proprioception for joint robotic control. TwinBrainVLA synergizes a frozen "Left Brain", which retains robust general visual reasoning, with a trainable "Right Brain", specialized for embodied perception, via a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. This design allows the Right Brain to dynamically query semantic knowledge from the frozen Left Brain and fuse it with proprioceptive states, providing rich conditioning for a Flow-Matching Action Expert to generate precise continuous controls. Extensive experiments on SimplerEnv and RoboCasa benchmarks demonstrate that TwinBrainVLA achieves superior manipulation performance compared to state-of-the-art baselines while explicitly preserving the comprehensive visual understanding capabilities of the pre-trained VLM, offering a promising direction for building general-purpose robots that simultaneously achieve high-level semantic understanding and low-level physical dexterity.
PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
Dec 18, 2025



Robotic generalization relies on physical intelligence: the ability to reason about state changes, contact-rich interactions, and long-horizon planning under egocentric perception and action. However, most VLMs are trained primarily on third-person data, creating a fundamental viewpoint mismatch for humanoid robots. Scaling robot egocentric data collection remains impractical due to high cost and limited diversity, whereas large-scale human egocentric videos offer a scalable alternative that naturally capture rich interaction context and causal structure. The key challenge is to convert raw egocentric videos into structured and reliable embodiment training supervision. Accordingly, we propose an Egocentric2Embodiment translation pipeline that transforms first-person videos into multi-level, schema-driven VQA supervision with enforced evidence grounding and temporal consistency, enabling the construction of the Egocentric2Embodiment dataset (E2E-3M) at scale. An egocentric-aware embodied brain, termed PhysBrain, is obtained by training on the E2E-3M dataset. PhysBrain exhibits substantially improved egocentric understanding, particularly for planning on EgoThink. It provides an egocentric-aware initialization that enables more sample-efficient VLA fine-tuning and higher SimplerEnv success rates (53.9\%), demonstrating effective transfer from human egocentric supervision to downstream robot control.
DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Oct 25, 2025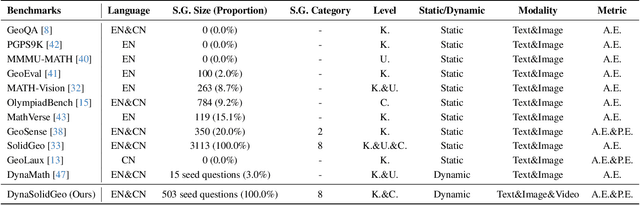

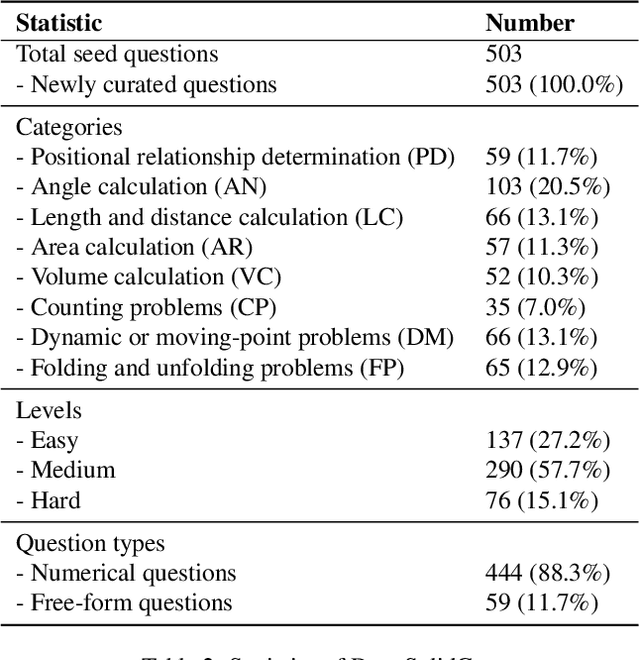

Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.